一,初识文件操作。
引子:
现在这个世界上,如果可以操作文件的所有软件都消失了,比如word,wps等等,此时你的朋友通过qq给你发过来一个文件,文件名是:美女模特空姐护士联系方式.txt,在座的所有男同学,那么你接受到这个文件之后,你的内心是否有一丝冲动,当然咱们不是那种闷骚的人,其实我们就是比较好奇,就是想要看看里面写的是什么,仅此而已,绝不联系。但是我说了所有可以操作文件的软件全部都没了,那么你是不是百爪挠心,火急火燎,哎呀。别急呀,你忘了么?你学过Python这门编程语言,这个语言肯定有能操控文件的功能。我相信在这种强大的动力下,你是可以,必须能学会的。
那么假设,现在让你用Python开发一个软件来操作这个文件,你觉得你需要什么必要参数呢?
文件路径:D:\美女模特空姐护士联系方式.txt (你想操作这个文件,必须要知道这个文件的位置)
编码方式:utf-8,gbk,gb2312.... (昨天刚讲完编码,文件其实就是数据的存储,数据存储你需要编码知道这个数据是以什么编码存储的)
操作模式:只读,只写,追加,写读,读写....


计算机系统分为:计算机硬件,操作系统,应用程序三部分。我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
此时你需要先利用软件创建一个文件,文件里面随便写一些内容,然后保存在任意磁盘(路径尽量要简单一些)中。
然后创建一个py文件,利用Python代码打开这个文件。
f = open('d:\护士少妇萝莉.txt',mode='r',encoding='utf-8')content = f.read()print(content)f.close()结果:标题很好 接下来就是对上面代码的解释: f: 就是一个变量,一般都会将它写成f,f_obj,file,f_handler,fh,等,它被称作文件句柄。 open:是Python调用的操作系统(windows,linux,等)的功能。 'd:\护士少妇萝莉.txt': 这个是文件的路径。 mode: 就是定义你的操作方式:r为读模式。 encoding: 不是具体的编码或者解码,他就是声明:此次打开文件使用什么编码本。一般来说:你的文件用什么编码保存的,就用什么方法打开,一般都是用utf-8(有些使用的是gbk)。 f.read():你想操作文件,比如读文件,给文件写内容,等等,都必须通过文件句柄进行操作。 close(): 关闭文件句柄(可以把文件句柄理解成一个空间,这个空间存在内存中,必须要主动关闭)。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r#2. 通过句柄对文件进行操作data=f.read()#3. 关闭文件f.close() 练习上面代码,可能出现的问题:
1. 路径问题。

这个是没有找到该文件,很可能是你的文件路径错了。
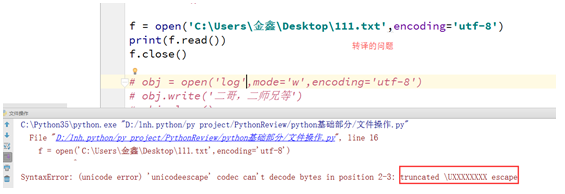
你的的路径里面的\与后面的字符产生了某种'化学反应',这个截图中的\D此时\就不是路径分隔符了,\D就有了特殊意义,其实跟\t,\n,换行符一样,所以针对这种情况,你应该这样解决:
解决方式一: 'C:\\Users\金鑫\Desktop\\111.txt' 凡是路径会发生化学反应的地方,多加一个\ 这样就是前面\对后面的\进行转译,告诉计算机这个只是想单纯的表示\路径而已。
解决方式二: r'C:\\Users\金鑫\Desktop\\111.txt' 在路径的整体前面加一个r。(推荐)
相对路径与绝对路径:
1.绝对路径:从磁盘根目录开始一直到文件名
2.相对路径:用一个文件夹下的文件,相对于当前这个程序所在的文件而言.如果在同一个文件中,则相对路劲就是这个文件名.如果再上一层文件夹则要使用../相对路径下,你就可以直接写文件名即可。
2. 编码的问题

这个问题就是你打开文件的编码与文件存储时的编码用的编码本不一致导致的。比如这个文件当时用word软件保存时,word软件默认的编码为utf-8,但是你利用python代码打开时,用的gbk,那么这个就会报错了。
文件操作的操作模式分为三个类:读,写,追加。每一类又有一些具体的方法,那么接下来我们就分类研究这些方法。
二. 文件操作:读
2.1 r模式
以只读方式打开文件,文件的指针将会放在文件的开头。是文件操作最常用的模式,也是默认模式,如果一个文件不设置mode,那么默认使用r模式操作文件。
举例说明:
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')msg = f.read()f.close()print(msg)结果:高圆圆刘亦菲张柏芝杨紫王菲 通过上面的例子可以看出来,我将小娃娃这个文件的内容全部读取出来了,那么读一个文件还可以怎么读取呢?下面我们研究一下不同的读文件的方法。
2.1.1 read()
read()将文件中的内容全部读取出来;弊端 如果文件很大就会非常的占用内存,容易导致内存奔溃.f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')msg = f.read()f.close()print(msg)结果:高圆圆刘亦菲张柏芝杨紫王菲 2.1.2 read(n)
read()读取的时候指定读取到什么位置
在r模式下,n按照字符读取。
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')msg = f.read(3)msg1 = f.read()f.close()print(msg)print(msg1)结果: 高圆圆刘亦菲张柏芝杨紫王菲 2.1.3 readline()
readline()读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个\n
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')msg1 = f.readline()msg2 = f.readline()msg3 = f.readline()msg4 = f.readline()f.close()print(msg1)print(msg2)print(msg3)print(msg4)结果:高圆圆刘亦菲张柏芝杨紫 解决这个问题只需要在我们读取出来的文件后边加一个strip()就OK了
f = open('path1/小娃娃.txt',mode='r',encoding='utf-8')msg1 = f.readline().strip()msg2 = f.readline().strip()msg3 = f.readline().strip()msg4 = f.readline().strip()f.close()print(msg1)print(msg2)print(msg3)print(msg4)结果:高圆圆刘亦菲张柏芝杨紫 2.1.4 readlines()
readlines() 返回一个列表,列表里面每个元素是原文件的每一行,如果文件很大,占内存,容易崩盘。
f = open('log',encoding='utf-8')print(f.readlines())f.close()# 结果['666666\n', 'fkja l;\n', 'fdkslfaj\n', 'dfsflj\n', 'df;asdlf\n', '\n', ] 上面这四种都太好,因为如果文件较大,他们很容易撑爆内存,所以接下来我们看一下第五种:
2.1.5 for循环
可以通过for循环去读取,文件句柄是一个迭代器,他的特点就是每次循环只在内存中占一行的数据,非常节省内存。
f = open('../path1/弟子规',mode='r',encoding='utf-8')for line in f: print(line) #这种方式就是在一行一行的进行读取,它就执行了下边的功能print(f.readline())print(f.readline())print(f.readline())print(f.readline())f.close() 注意点:读完的文件句柄一定要关闭
2.2 rb模式
rb模式:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。记住下面讲的也是一样,带b的都是以二进制的格式操作文件,他们主要是操作非文字文件:图片,音频,视频等,并且如果你要是带有b的模式操作文件,那么不用声明编码方式。
可以网上下载一个图片给同学们举例:
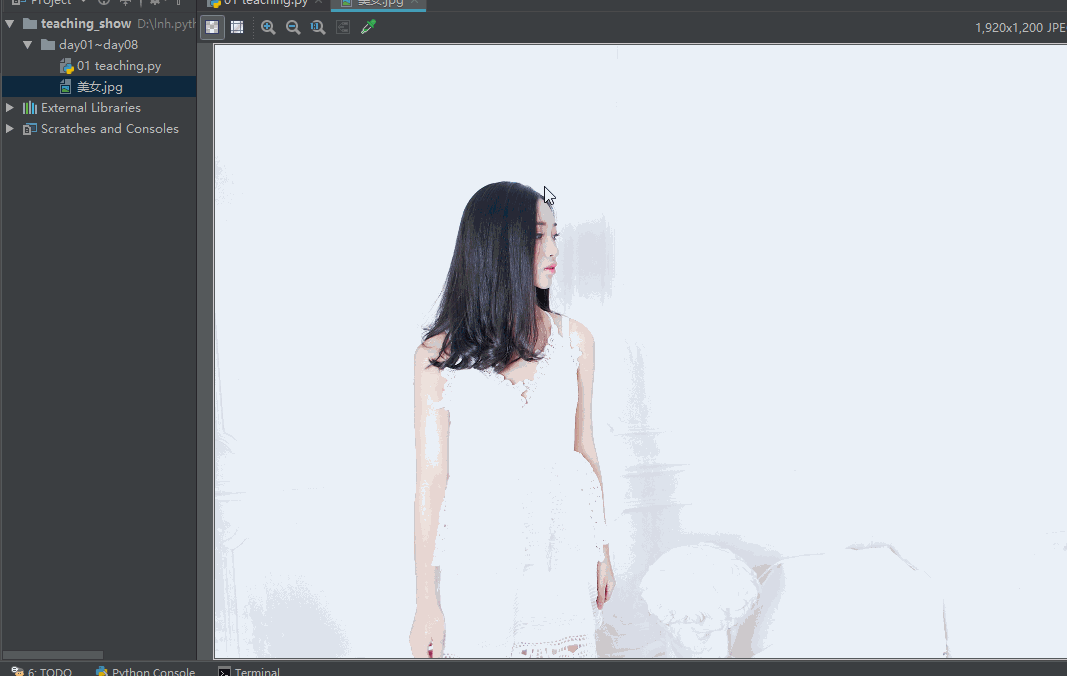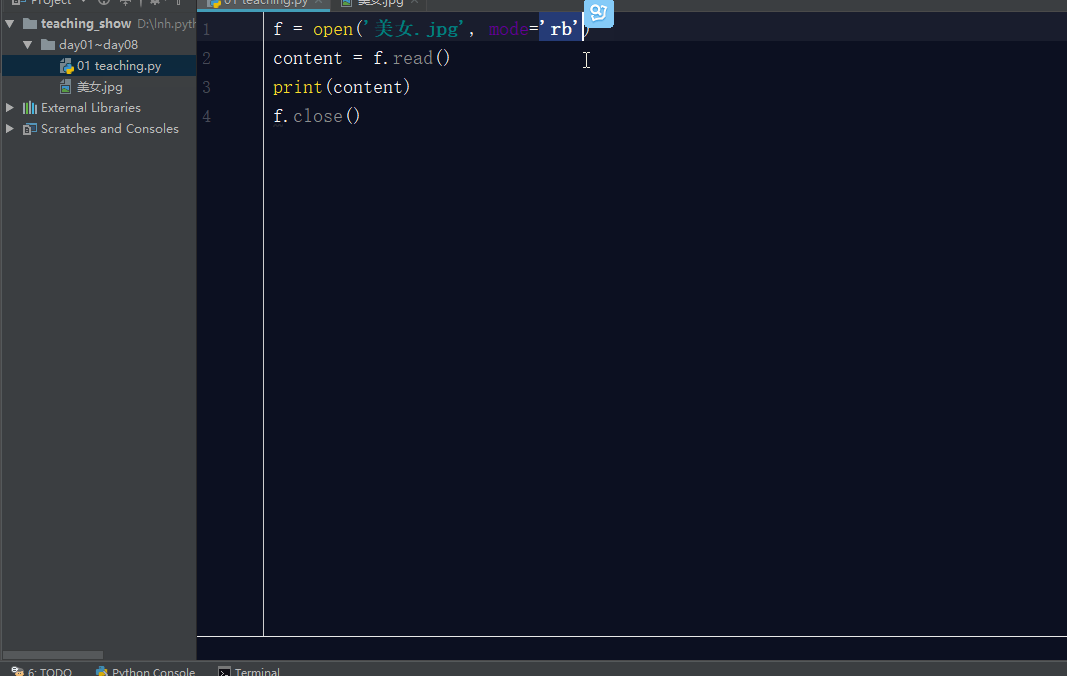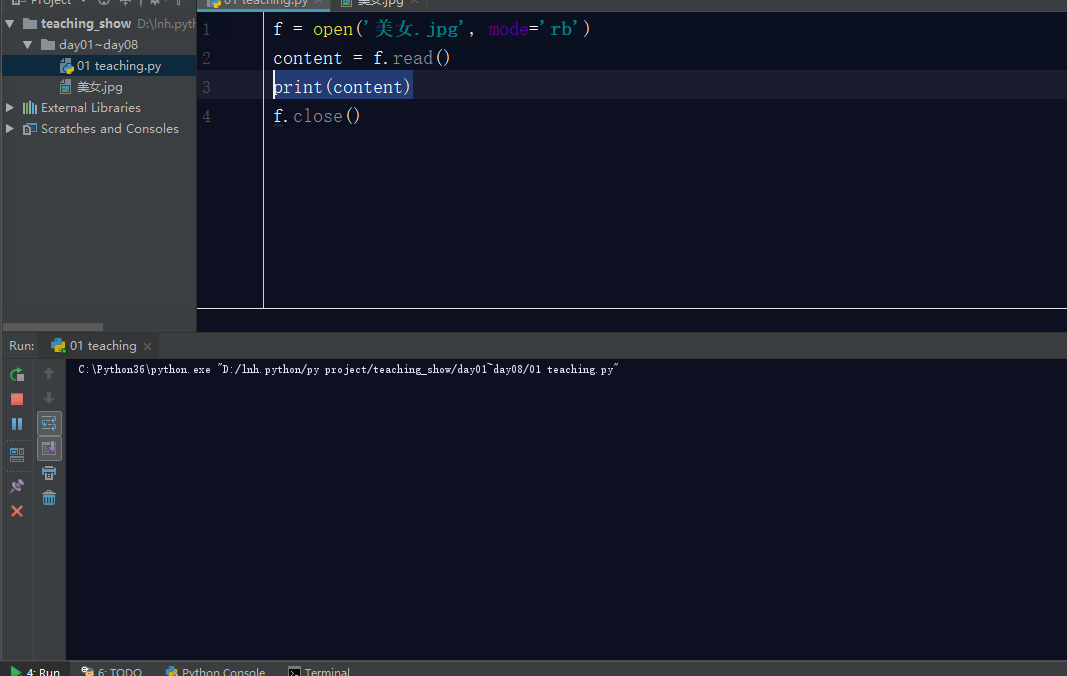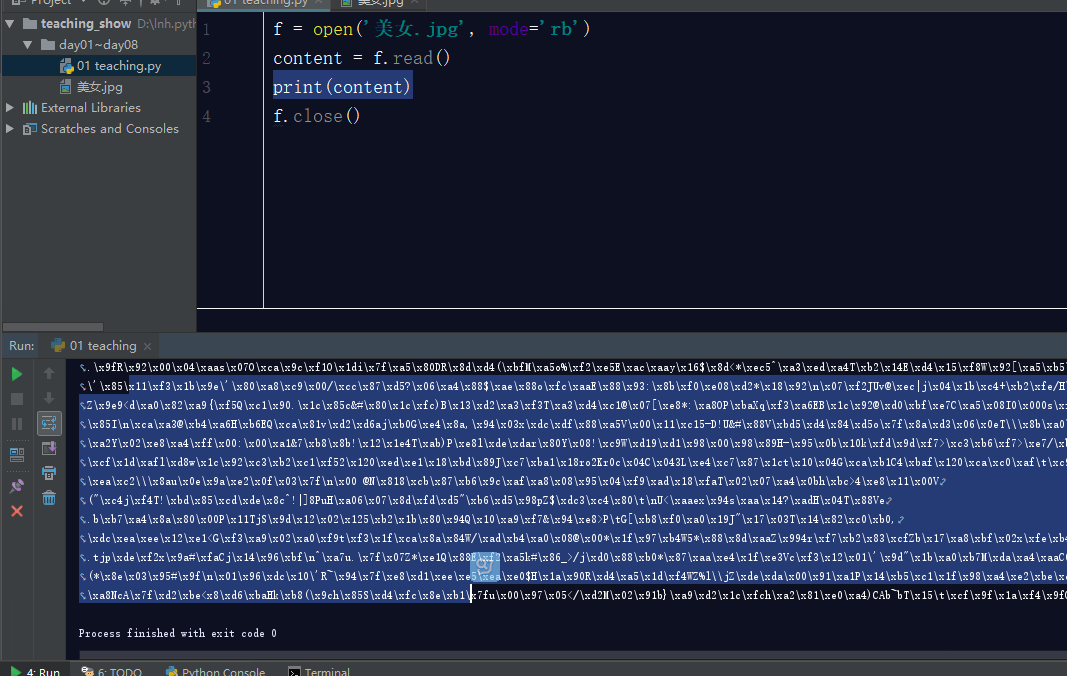
当然rb模式也有read read(n) readline(),readlines() for循环这几种方法,我在这就不一一演示了。
三. 文件操作:写
第二类就是写,就是在文件中写入内容。这里也有四种文件分类主要四种模式:w,wb,w+,w+b,我们只讲w,wb。
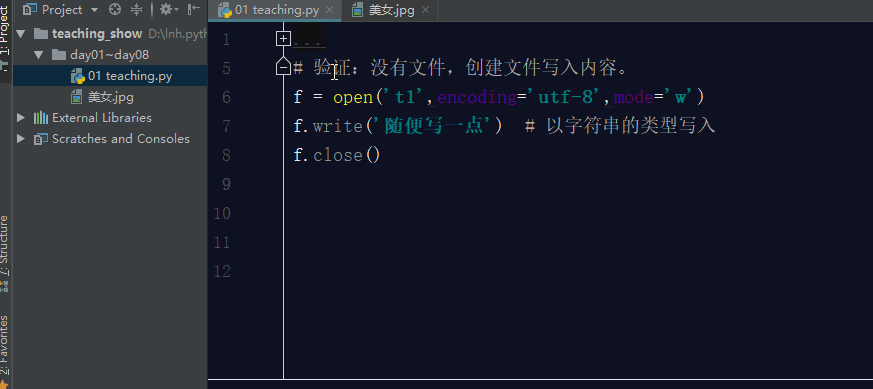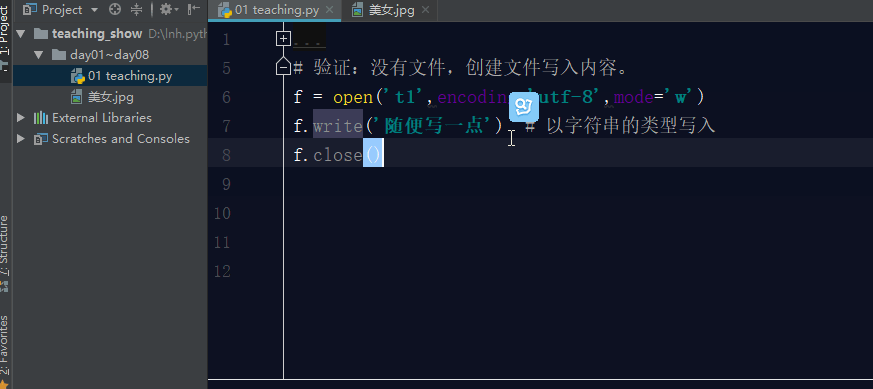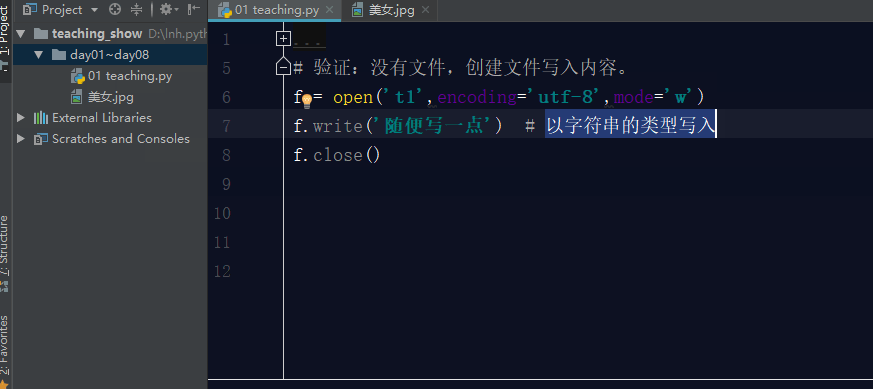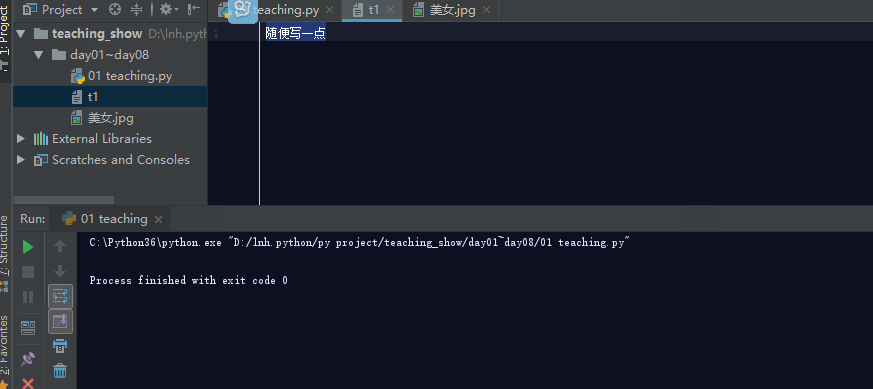
3.1 w模式
如果文件不存在,利用w模式操作文件,那么它会先创建文件,然后写入内容.
如果文件存在,利用w模式操作文件,先清空原文件内容,在写入新内容。
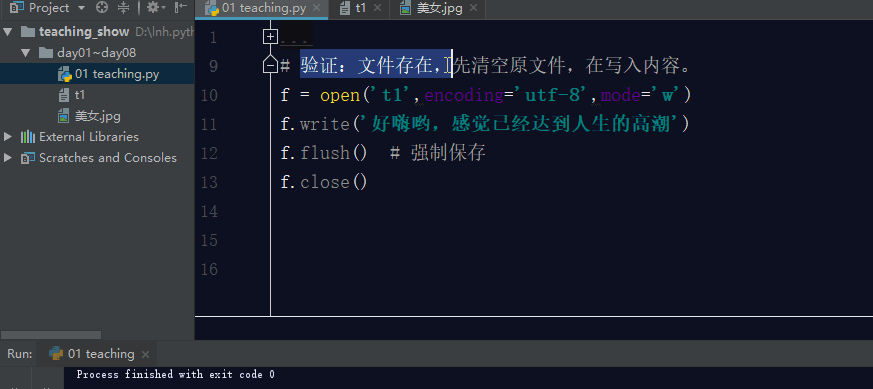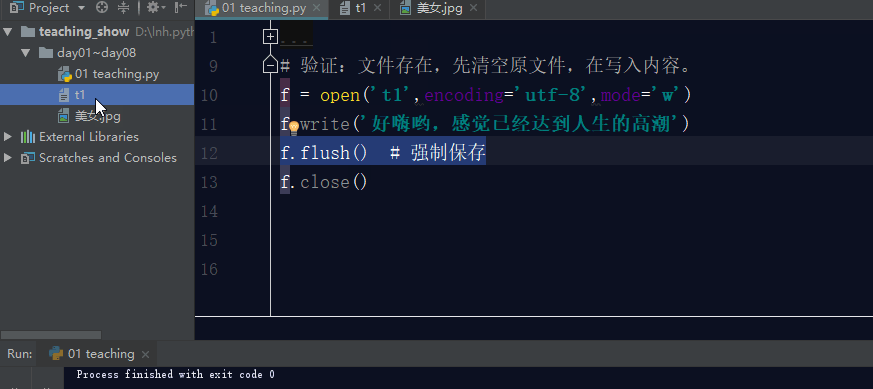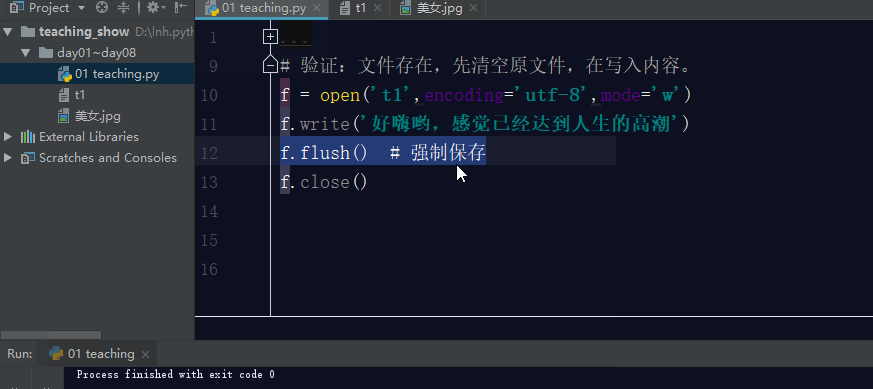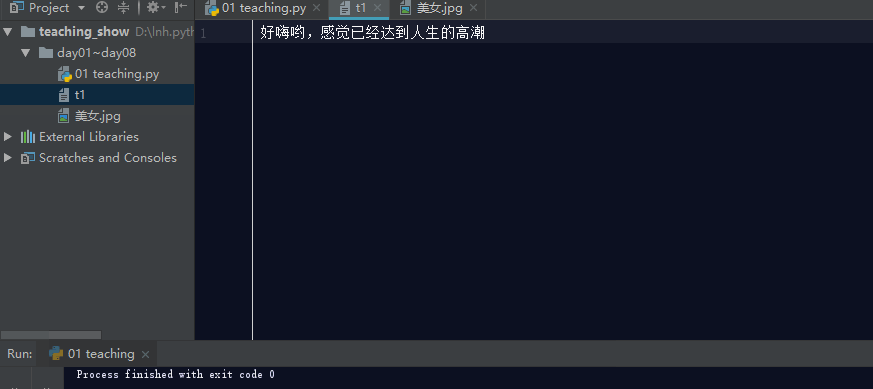
3.2 wb模式
wb模式:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如:图片,音频,视频等。
举例说明:
我先以rb的模式将一个图片的内容以bytes类型全部读取出来,然后在以wb将全部读取出来的数据写入一个新文件,这样我就完成了类似于一个图片复制的流程。具体代码如下:

四. 文件操作:追加
第三类就是追加,就是在文件中追加内容。这里也有四种文件分类主要四种模式:a,ab,a+,a+b,我们只讲a。
4.1 a模式
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
如果文件不存在,利用a模式操作文件,那么它会先创建文件,然后写入内容。

如果文件存在,利用a模式操作文件,那么它会在文件的最后面追加内容。
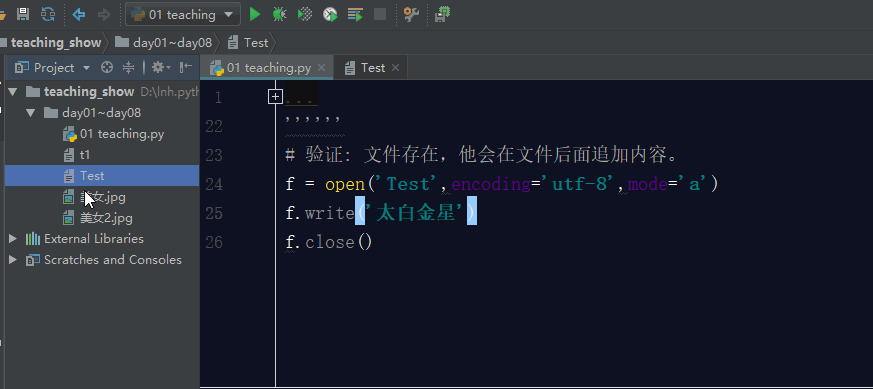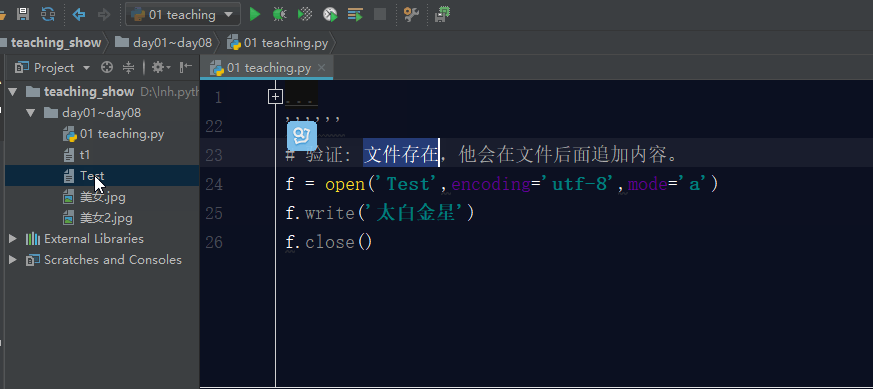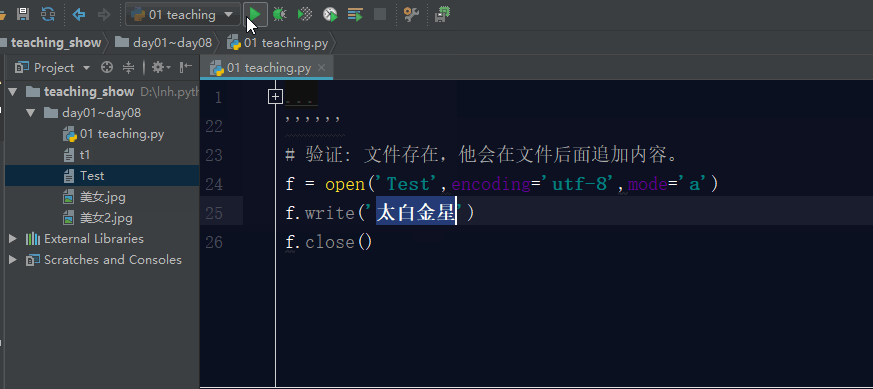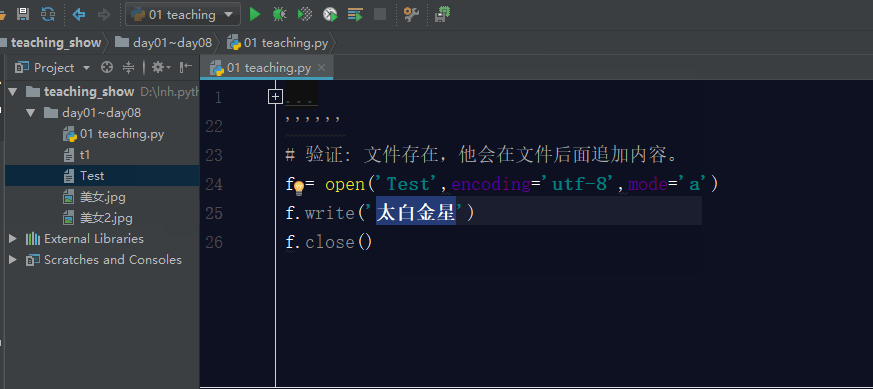
五. 文件操作的其他模式
大家发现了没有,咱们还有一种模式没有讲,就是那种带+号的模式。什么是带+的模式呢?+就是加一个功能。比如刚才讲的r模式是只读模式,在这种模式下,文件句柄只能进行类似于read的这读的操作,而不能进行write这种写的操作。所以我们想让这个文件句柄既可以进行读的操作,又可以进行写的操作,那么这个如何做呢?这就是接下来要说这样的模式:r+ 读写模式,w+写读模式,a+写读模式,r+b 以bytes类型的读写模式.........
在这里咱们只讲一种就是r+,其他的大同小异,自己可以练练就行了。
#1. 打开文件的模式有(默认为文本模式):r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】w,只写模式【不可读;不存在则创建;存在则清空内容】a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)rb wbab注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码#3,‘+’模式(就是增加了一个功能)r+, 读写【可读,可写】w+,写读【可写,可读】a+, 写读【可写,可读】#4,以bytes类型操作的读写,写读,写读模式r+b, 读写【可读,可写】w+b,写读【可写,可读】a+b, 写读【可写,可读】
5.1 r+模式
r+: 打开一个文件用于读写。文件指针默认将会放在文件的开头。

注意:如果你在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会讲原内容覆盖掉,直到覆盖到你写完的内容,然后在后面开始读取。
六. 文件操作的其他功能
6.1 read(n)
1. 文件打开方式为文本模式时,代表读取n个字符
2. 文件打开方式为b模式时,代表读取n个字节
6.2 seek()
seek(n)光标移动到n位置,注意: 移动单位是byte,所有如果是utf-8的中文部分要是3的倍数
通常我们使用seek都是移动到开头或者结尾
移动到开头:seek(0)
移动到结尾:seek(0,2) seek的第二个参数表示的是从哪个位置进行偏移,默认是0,表示开头,1表示当前位置,2表示结尾
f = open("小娃娃", mode="r+", encoding="utf-8")f.seek(0) # 光标移动到开头content = f.read() # 读取内容, 此时光标移动到结尾print(content)f.seek(0) # 再次将光标移动到开头f.seek(0, 2) # 将光标移动到结尾content2 = f.read() # 读取内容. 什么都没有print(content2)f.seek(0) # 移动到开头f.write("张国荣") # 写入信息. 此时光标在9 中文3 * 3个 = 9f.flush()f.close() 6.3 tell()
使用tell()可以帮我们获取当前光标在什么位置
f = open("小娃娃", mode="r+", encoding="utf-8")f.seek(0) # 光标移动到开头content = f.read() # 读取内容, 此时光标移动到结尾print(content)f.seek(0) # 再次将光标移动到开头f.seek(0, 2) # 将光标移动到结尾content2 = f.read() # 读取内容. 什么都没有print(content2)f.seek(0) # 移动到开头f.write("张国荣") # 写入信息. 此时光标在9 中⽂文3 * 3个 = 9print(f.tell()) # 光标位置9f.flush()f.close() 6.4 readable(),writeable()
f = open('Test',encoding='utf-8',mode='r')print(f.readable()) # Trueprint(f.writable()) # Falsecontent = f.read()f.close() class TextIOWrapper(_TextIOBase): """ Character and line based layer over a BufferedIOBase object, buffer. encoding gives the name of the encoding that the stream will be decoded or encoded with. It defaults to locale.getpreferredencoding(False). errors determines the strictness of encoding and decoding (see help(codecs.Codec) or the documentation for codecs.register) and defaults to "strict". newline controls how line endings are handled. It can be None, '', '\n', '\r', and '\r\n'. It works as follows: * On input, if newline is None, universal newlines mode is enabled. Lines in the input can end in '\n', '\r', or '\r\n', and these are translated into '\n' before being returned to the caller. If it is '', universal newline mode is enabled, but line endings are returned to the caller untranslated. If it has any of the other legal values, input lines are only terminated by the given string, and the line ending is returned to the caller untranslated. * On output, if newline is None, any '\n' characters written are translated to the system default line separator, os.linesep. If newline is '' or '\n', no translation takes place. If newline is any of the other legal values, any '\n' characters written are translated to the given string. If line_buffering is True, a call to flush is implied when a call to write contains a newline character. """ def close(self, *args, **kwargs): # real signature unknown 关闭文件 pass def fileno(self, *args, **kwargs): # real signature unknown 文件描述符 pass def flush(self, *args, **kwargs): # real signature unknown 刷新文件内部缓冲区 pass def isatty(self, *args, **kwargs): # real signature unknown 判断文件是否是同意tty设备 pass def read(self, *args, **kwargs): # real signature unknown 读取指定字节数据 pass def readable(self, *args, **kwargs): # real signature unknown 是否可读 pass def readline(self, *args, **kwargs): # real signature unknown 仅读取一行数据 pass def seek(self, *args, **kwargs): # real signature unknown 指定文件中指针位置 pass def seekable(self, *args, **kwargs): # real signature unknown 指针是否可操作 pass def tell(self, *args, **kwargs): # real signature unknown 获取指针位置 pass def truncate(self, *args, **kwargs): # real signature unknown 截断数据,仅保留指定之前数据 pass def writable(self, *args, **kwargs): # real signature unknown 是否可写 pass def write(self, *args, **kwargs): # real signature unknown 写内容 pass def __getstate__(self, *args, **kwargs): # real signature unknown pass def __init__(self, *args, **kwargs): # real signature unknown pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __next__(self, *args, **kwargs): # real signature unknown """ Implement next(self). """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass buffer = property(lambda self: object(), lambda self, v: None, lambda self: None) # default closed = property(lambda self: object(), lambda self, v: None, lambda self: None) # default encoding = property(lambda self: object(), lambda self, v: None, lambda self: None) # default errors = property(lambda self: object(), lambda self, v: None, lambda self: None) # default line_buffering = property(lambda self: object(), lambda self, v: None, lambda self: None) # default name = property(lambda self: object(), lambda self, v: None, lambda self: None) # default newlines = property(lambda self: object(), lambda self, v: None, lambda self: None) # default _CHUNK_SIZE = property(lambda self: object(), lambda self, v: None, lambda self: None) # default _finalizing = property(lambda self: object(), lambda self, v: None, lambda self: None) # default3.x
七. 打开文件的另一种方式
咱们打开文件都是通过open去打开一个文件,其实Python也给咱们提供了另一种方式:with open() as .... 的形式,那么这种形式有什么好处呢?
# 1,利用with上下文管理这种方式,它会自动关闭文件句柄。with open('t1',encoding='utf-8') as f1: f1.read() # 2,一个with 语句可以操作多个文件,产生多个文件句柄。with open('t1',encoding='utf-8') as f1,\ open('Test', encoding='utf-8', mode = 'w') as f2: f1.read() f2.write('老男孩老男孩') 这里要注意一个问题,虽然使用with语句方式打开文件,不用你手动关闭文件句柄,比较省事儿,但是依靠其自动关闭文件句柄,是有一段时间的,这个时间不固定,所以这里就会产生问题,如果你在with语句中通过r模式打开t1文件,那么你在下面又以a模式打开t1文件,此时有可能你第二次打开t1文件时,第一次的文件句柄还没有关闭掉,可能就会出现错误,他的解决方式只能在你第二次打开此文件前,手动关闭上一个文件句柄。
八. 文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os # 调用系统模块with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: data=read_f.read() #全部读入内存,如果文件很大,会很卡 data=data.replace('alex','SB') #在内存中完成修改 write_f.write(data) #一次性写入新文件os.remove('a.txt') #删除原文件os.rename('.a.txt.swap','a.txt') #将新建的文件重命名为原文件 方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import oswith open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: for line in read_f: line=line.replace('alex','SB') write_f.write(line)os.remove('a.txt')os.rename('.a.txt.swap','a.txt') 1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数。apple 10 3tesla 100000 1mac 3000 2lenovo 30000 3chicken 10 3通过代码,将其构建成这种数据类型:[{ 'name':'apple','price':10,'amount':3},{ 'name':'tesla','price':1000000,'amount':1}......] 并计算出总价钱。2,有如下文件:-------alex是老男孩python发起人,创建人。alex其实是人妖。谁说alex是sb?你们真逗,alex再牛逼,也掩饰不住资深屌丝的气质。----------将文件中所有的alex都替换成大写的SB。